
Python 웹사이트 크롤링하는 방법
오늘은 파이썬을 이용해서 사이트를 크롤링하는 방법을 알아보겠습니다. 먼저 크롤링을 알아보기 전에 크롤링, 파싱, 스크래핑이라는 자주 사용되는 단어에 대해서 정의하고 가보겠습니다.
사이트 크롤링?
크롤링(crawling)은 인터넷(web) 상에 존재하는 콘텐츠(Contents)를 수집하는 일련의 작업 (프로그래밍으로 자동화 가능)을 뜻하는데요.
좀 더 기술적으로 들어가면 기본적으로 웹에 있는 HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법을 말합니다. 이 때 사이트가 Open API(Rest API)를 제공하는 서비스라면 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법이기도 합니다.
파이썬에서는 Selenium등 패키지를 활용해서 브라우저를 프로그래밍으로 조작하여, 필요한 데이터만 추출하기도 합니다.
파싱
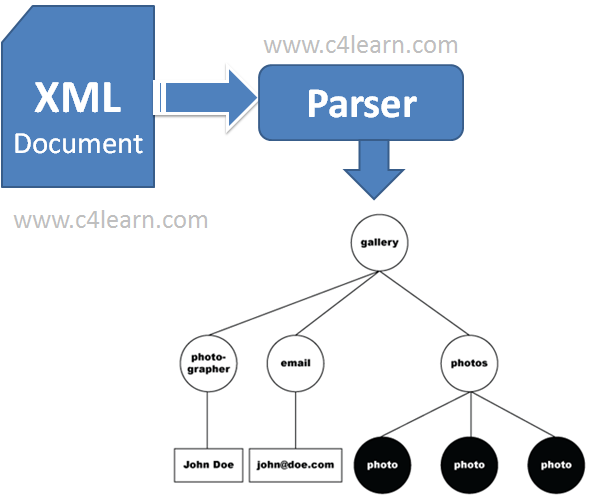
파싱(parsing)은 구문 분석이라고 하는데요. 문장이 이루고 있는 구성 성분을 분해하고 분해된 성분의 위계 관계를 분석하여 구조를 결정하는 것입니다. 즉 크롤링을 통해 가져온 데이터를 분해 분석하여 원하는 형태로 조립하고 다시 빼내는 일련의 프로그램을 말합니다. 웹상에서 주어진 정보를 내가 원하는 형태로 가공하여 서버에서 불러들이는 것을 말합니다.
또한 자주 사용되는 단어가 스크래핑인데요.
스크래핑
스크래핑은 크롤링과 자주 혼용되어 사용되는데요. 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 심층 분석이 필요할 때 유용합니다. 또한 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기가 좋습니다.
한편 웹 스크래핑은 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인트를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용한데요. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다는 장점이 있습니다.
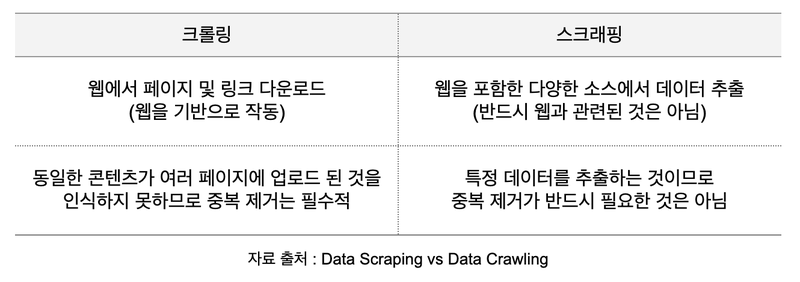
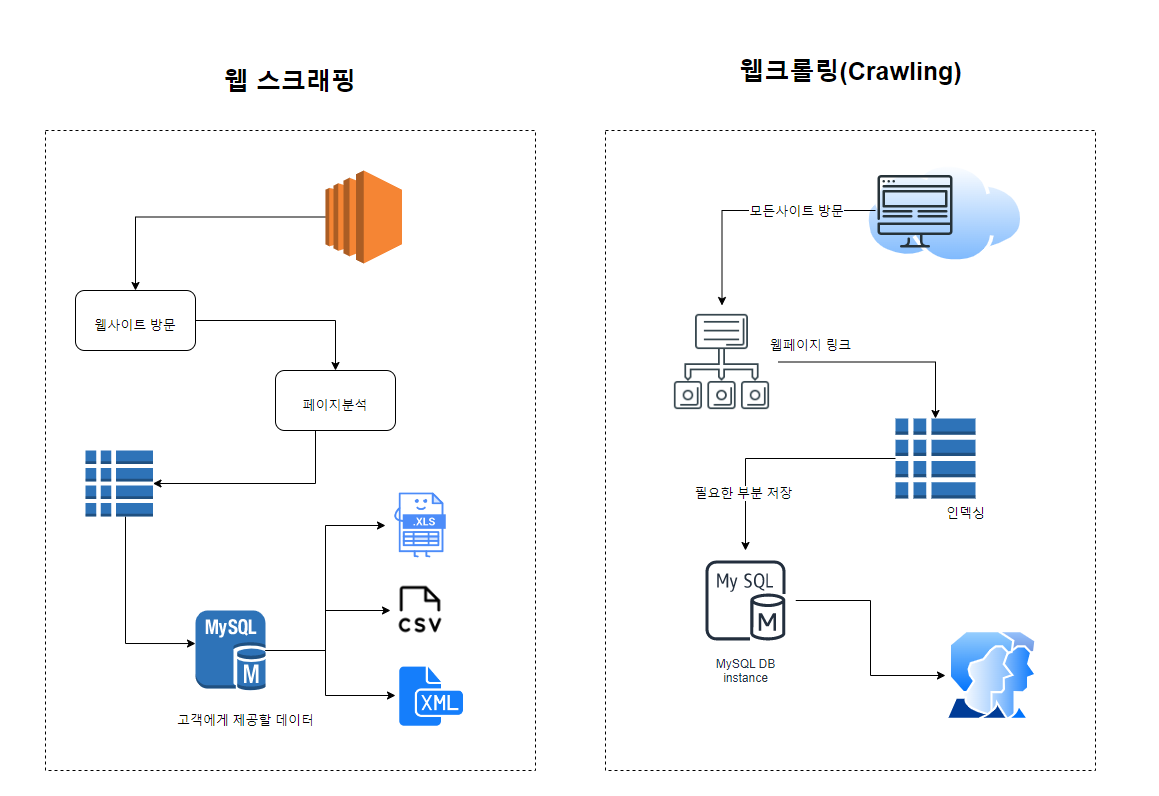
즉 크롤링은 웹사이트의 전체를 가져오는 것을 말한다면, 스크래핑은 특정 데이터만을 추출하는 것을 이야기 합니다.
프로그램 개발시에는 두가지를 엄격하게 구분하지 않고 프로그램 개발 목적에 맞춰 적절하게 혼합하여 활용하여 개발하는 것이 일반적입니다.
파이썬 크롤링 실습
그럼 간단하게 파이썬을 이용하여 크롤링 실습을 해보겠습니다. 파이썬을 이용한 사이트 크롤링의 경우 일반적으로 requests라는 https를 분석하는 패키지와 Beautifulsoup4이라는 파서, 그리고 데이터 입출력을 위해서 pandas 패키지를 통해 작성하는 것이 일반적입니다.
파이썬 설치 후 3개의 패키지를 설치해줍니다.
pip install requests
pip install beautifulsoup4
pip install pandas
이후 간단한 뼈대 파일을 만들어보겠습니다. 크게 3단계로 정리해보았는데요.
먼저 사용할 패키지를 불러옵니다. 3개의 패키지를 import 문을 통해서 불러옵니다.
이후 크롤링할 사이트를 불러오는데요. naver를 테스트해보겠습니다.
header값은 혹시 사이트가 프로그램으로 접속을 막을 경우 추가하여 사용합니다.
이후 request로 불러온 것을 html이라는 변수에 저장하는 형태입니다.
#1. 패키지 불러오기
from bs4 import BeautifulSoup
import requests
import pandas as pd
#2. 사이트 불러오기, 헤더 추가
url = "https://www.naver.com"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#2-2 사이트 응답 처리, 에러시 예외 처리
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # HTTPError 발생 가능
except requests.exceptions.RequestException as e:
print("Error occurred: ", e)
#3. 페이지 불러오기
html = response.text
print(html)이를 실행하면 네이버 페이지를 구성하는 전체 요소를 불러오게 됩니다.

이 중에서 자신에게 필요한 정보만 찾아야 하는데요. 이제 내가 원하는 정보만 찾는 방법을 알아보겠습니다.
원하는 웹사이트 항목 크롤링하기
먼저 앞서 살펴본 beautifulsoup4라는 파서를 통해서 크롤링한 데이터를 정리해보겠습니다.
예시를 위해 네이버 농구 사이트의 정보를 크롤링하는 프로그램을 만들어보겠습니다.
파서를 이용하면 구문별로 나눠서 보여주기 때문에 보다 편리하게 볼 수 있습니다.
soup = BeautifulSoup(html, 'html.parser')
print(soup)
먼저 사이트를 크롤링하기 위해서는 사이트를 분석할 필요가 있는데요.
크롬에서 F12를 눌러 개발자 도구를 활성화한 다음 크롤링하고자 하는 정보가 있는 곳을 클릭합니다.
경기일정에 대한 정보는 sch_tb와 sch_tb2에 위치한 것을 확인할 수 있는데요.
이 때 html문법을 알면 좀더 편리한데요. div태그는 Division의 약자로 웹사이트의 레이아웃(전체적인 틀)을 만들때 주로 사용합니다. div는 웹페이지에서 논리적 구분을 정의하는 태그입니다.
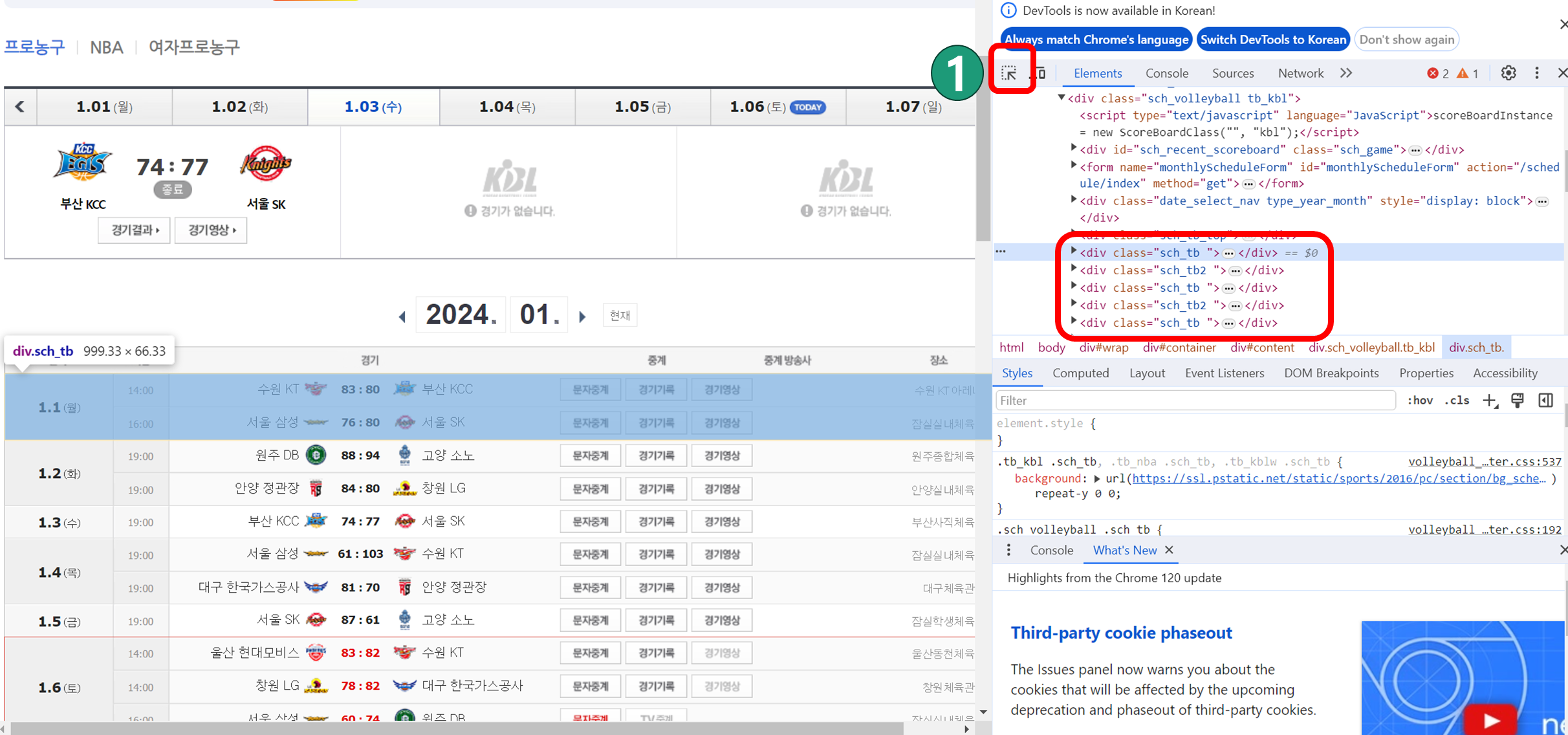
그럼 먼저 soupData라는 변수에 sch_tb, sch_tb2를 모두 넣은 다음
반복문을 통해서 개별 항목의 날짜/시간/홈팀/원정팀/구장 정보를 가져옵니다.
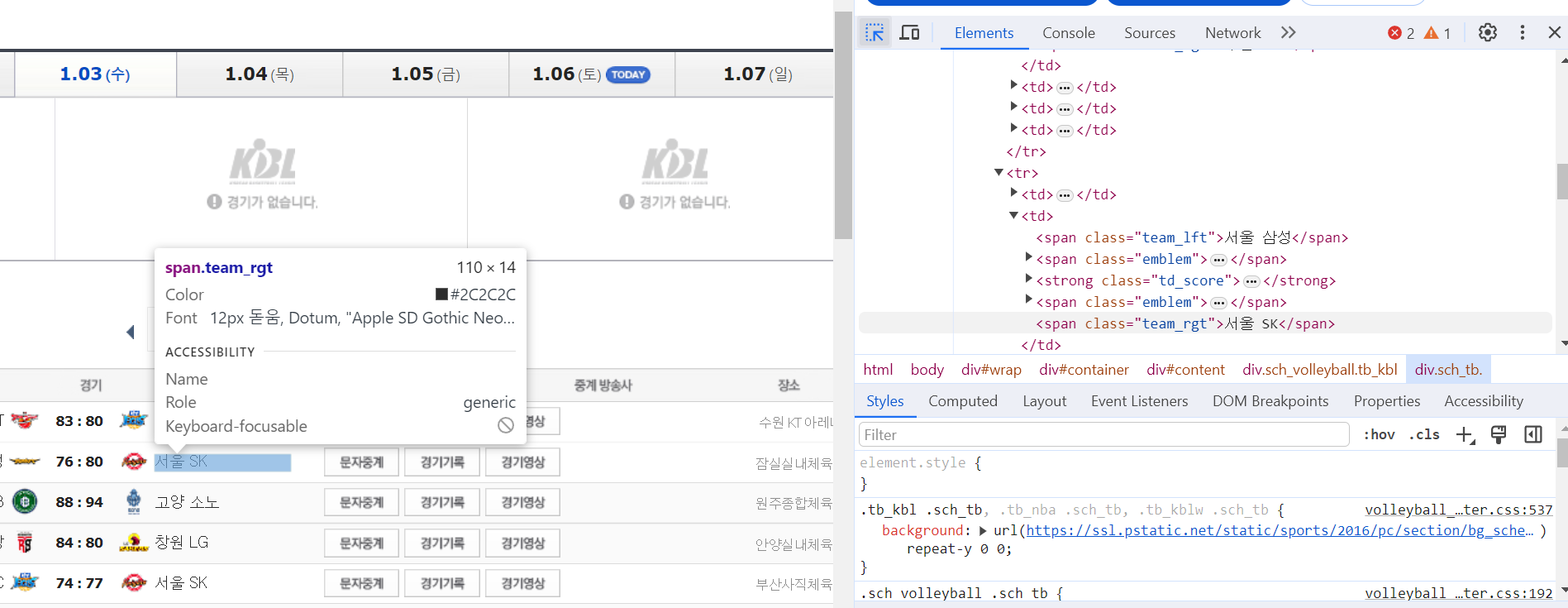
개별 항목에 대해서 마우스를 가져다 대면 어떤 항목으로 찾을 수 있는지 확인 가능합니다.
#soupData에 경기일정 추가하기
soupData = [soup.findAll("div", {"class" : "sch_tb"}), soup.findAll("div", {"class" : "sch_tb2"})]
dataList = []
#경기일정에 데이터 세부항목 구분
for data_tb in soupData:
for data in data_tb:
data_val = data.findAll("span",{"class" : "td_date"})[0].text
match_cnt = data.findAll("td")[0]['rowspan']
if int(match_cnt) == 5 :
continue
for i in range(0, int(match_cnt)):
matchData = {}
matchData["날짜"] = data_val
matchData["시간"] = data.findAll("tr")[i].findAll("span",{"class":"td_hour"})[0].text
matchData["홈팀"] = data.findAll("tr")[i].findAll("span",{"class":"team_lft"})[0].text
matchData["원정팀"] = data.findAll("tr")[i].findAll("span",{"class":"team_rgt"})[0].text
matchData["구장"] = data.findAll("tr")[i].findAll("span",{"class":"td_stadium"})[0].text
dataList.append(matchData)
df = pd.DataFrame(dataList)
print(df)
df.T.to_csv('basket.csv', encoding='cp949') 마지막으로 판다스를 통해서 dataframe으로 만들고 csv로 추출하였습니다.
사이트 크롤링 결과는 아래와 같습니다.

그럼 잘 사용하시기 바랍니다.





